Message Passing Interface (MPI)
[ Features ]
MPI/ES is a message passing library based on the MPI-1 and MPI-2
standards and provides high-speed communication capability that
fully exploits the features of IN and shared memory. It can
be used for both intra- and inter-node parallelization. An MPI
process is assigned to an AP in the flat parallelization, or
to a PN that contains microtasks or OpenMP threads in the hybrid
parallelization. MPI/ES libraries are designed and optimized
carefully to achieve highest performance of communication on
the ES architecture in both of the parallelization manner.
[ Evaluation ]
Here, a result on performance measurements of MPI libraries
implemented on the ES is presented as well as a virtual memory
space allocation [1].
A memory space of a process on the ES is divided into two kinds
of spaces which are called local memory (LMEM) and global memory
(GMEM). These memory spaces can be assigned to buffers of MPI
functions. Especially, GMEM is addressed globally over nodes
and can only be accessed by the RCU. The GMEM area can be shared
by every MPI processes allocated to different nodes with a global
memory address.
The behavior of MPI communications is different according to
the memory area where the buffers to be transferred are resided.
It is classified into four cases.
| Case 1 | Data that are stored in LMEM of a process A are transferred to LMEM of another process B on the same nodes. In this case, GMEM is used as general shared memory. The data in LMEM of the process A are copied into an area of GMEM of the process A first. Next, the data in GMEM of the process A are copied into LMEM of the process B. |
| Case 2 | Data that are stored
in LMEM of the process A are transferred to LMEM of a
processor C invoked in a different node. Firstly, the
data in LMEM of process A are copied into GMEM of the
process A. Next, the data in GMEM of the process A are copied into GMEM of the process C via the crossbar switch using INA instructions. Finally, the data in GMEM of the process C are copied into LMEM of the process C. |
| Case 3 | Data that are stored in GMEM of the process A are transferred to GMEM of the processor B in the same node, the data in GMEM of the process A are copied by one copy operation directly into GMEM of the process B. |
| Case 4 | Data that are stored in GMEM of the process A are transferred to GMEM of the processor C invoked in a different node. The data in GMEM of the process A are copied directly into GMEM of the process C via the crossbar switch using INA instruction. |
The performance of the ping-pong pattern implemented by either MPI_Send/MPI_ Irecv functions or MPI_Isend/MPI_Irecv functions is evaluated on the ES. Two MPI processes are invoked according to the four cases described above and the performance of the two send functions are measured by changing message size to be transferred. The evaluation results are shown in Figure 8.
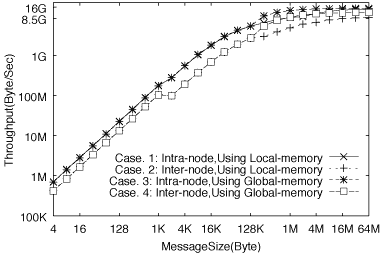
Figure 8: Throughput of ping-pong using MPI_Send
For intra-node communication, the maximum throughput is 14.8GB/s
in Case 3, half of the peak is achieved when message length
is larger than 256KB, and the startup cost is 1.38 μsec. For
inter-node communication, the maximum throughput is 11.8GB/s
in Case 4, half of the peak is achieved when message length
is larger than 512KB, and the startup cost is 5.58 μsec. The
gaps at the message size of near 1KB and near 128KB in the figure
are caused by changing the communication method in the MPI functions,
which are changed according to the message length.
The performances of the ping pattern implemented by three RMA
functions of MPI_Get, MPI_Put, and MPI_Accumulate with sum operation
are measured by invoking two MPI processes over two nodes. The
throughputs are depicted in Figure 9. The maximum throughputs
for MPI_Get, MPI_Put, and MPI_Accumulate are 11.62GB/s, 11.62GB/s,
and 3.16GB/s, respectively. The startup costs are 6.36μsec,
6.68μsec, and 7.65μsec.

Figure 9: Throughput of ping using RMA functions
We also measured the time required to barrier synchronization among nodes and the time is about 3.25μsec independently of the number of nodes.