システムの概要(ES)
Message Passing Interface (MPI)
【機能】
MPI/ESは、MPI-1仕様およびMPI-2仕様に基づくメッセージ通信ライブラリであり、INと共有メモリの機能を利用した高速な通信を実現する。ノード内並列化とノード間並列化の両方で利用できる。一つのMPIプロセスは、フラット並列化では一つのAPに、ハイブリッド並列化では一つのPN(一つ以上のマイクロタスクまたはOpenMPスレッドを含み得る)に割り当てられる。MPI/ESライブラリは、このどちらの並列化方法においても最大の性能を発揮できるように設計・最適化されている。
【評価】
本章では、ESに実装されているMPIライブラリの性能評価の結果を示す。
ES上で動くプロセスのメモリ空間は二種類に分類される。それらは、ローカルメモリ(LMEM)とグローバルメモリ(GMEM)と呼ばれ、それぞれMPI
関数のバッファに割り当てることができる。このうち、GMEMは全ノードにグローバルなアドレスを持ち、RCUのみがアクセスできる。別々のノードに割り付けられているMPIプロセスでも、グローバルメモリアドレスによってGMEMの領域を共有することができる。
MPI通信の振る舞いは、転送すべきバッファが割り付けられているメモリ領域によって異なり、次の四つに分類できる。
| Case 1 | プ ロセスAのLMEMに格納されているデータを、同一ノード内のプロセスBのLMEMへ転送する場合。この場合には、GMEMは通常の共有メモリとして使用 される。プロセスAのLMEM内のデータは、まずプロセスAのGMEMへコピーされる。次に、プロセスAのGMEMからプロセスBのLMEMへコピーされ る。 |
| Case 2 | プ ロセスAのLMEMに格納されているデータを、別ノード上のプロセスCのLMEMへ転送する場合。最初に、プロセスAのLMEM内のデータは、プロセスA のGMEMへコピーされる。次に、プロセスAのGMEM内のデータは、INA命令によって、クロスバスイッチを介してプロセスCのGMEMへ転送される。 最後に、プロセスCのGMEM内のデータは、プロセスCのLMEMへコピーされる。 |
| Case 3 | プロセスAのGMEMに格納されてい るデータを、同一ノード内のプロセスBのGMEMへ転送する場合。プロセスAのGMEM内のデータは、一回のコピー処理によって、プロセスBのGMEMへ 直接コピーされる。 |
| Case 4 | プロセスAのGMEMに格納されてい るデータを、別ノード上のプロセスCのGMEMへ転送する場合。プロセスAのGMEM内のデータは、INA命令によって、クロスバスイッチを介してプロセ スCのGMEMへ直接転送される。 |
MPI_Send/MPI_Irecv 関数またはMPI_Isend/MPI_Irecv関数で実装したping-pongパターン通信の性能をES上で評価した。二つのMPIプロセスを上述の四つの場合に従って起動し、メッセージのサイズを変化させて各々の場合の二種のsend関数の性能を測定した。評価の結果を図8に示す。
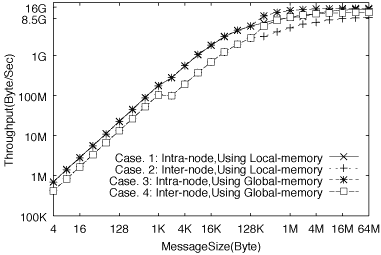
図8: MPI_Sendを用いたping-pong通信のスループット
ノード内通信では、最大スループットはCase 3の14.8GB/Sである。メッセージ長が256KB以上でピークの半分の性能が得られ、スタートアップのコストは1.38μsecになる。ノード間通信では、最大スループットはCase
4の11.8GBである。メッセージ長が512KB以上でピークの半分の性能が得られ、スタートアップのコストは5.58μsecである。メッセージ長が
1KBと128KBの付近に見られるギャップは、MPI関数がメッセージ長によって通信方法を切り替えるために起きる。
MPI_Get, MPI_PutおよびMPI_Accumulate(総和)の3つのRMA関数で実装したping通信の性能を、異なるノード上に起動した2つのMPIプロセスに対して測定した。図9にスループットを示す。MPI_Get,
MPI_Put, MPI_Accumulateの最大スループットはそれぞれ11.62GB/s, 11.62GB/s, 3.16GB/Sであり、スタートアップのコストはそれぞれ6.36μsec,
6.68μsec, 7.65μsecである。
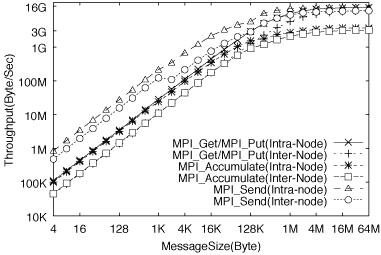
図9:RMA関数を用いたping通信のスループット
また、ノード間のバリア同期に要する時間を測定したところ、ノード数に関わらず約3.25μsecという結果が得られた。