
研究内容紹介
「大海撈針にも楽な道がある
デジタル・タンパク質スクリーニング・システム」
張 翼 研究員
Accurate high-throughput screening based on digital protein synthesis in a massively parallel femtoliter droplet arrayYi Zhang, Yoshihiro Minagawa, Hiroto Kizoe, Kentaro Miyazaki, Ryota Iino, Hiroshi Ueno, Kazuhito V. Tabata, Yasuhiro Shimane, Hiroyuki Noji
Science Advances, 2019, 5, 8, eaav8185
日本語 English 中国語
紹介を始める前に、、、
だいぶ間があいてしまいました「研究内容紹介シリーズ 」、実は当初予定の第3回の執筆依頼者に「忙しいから落ち着いたら」と言われ半年以上待ち続け、「いい加減書いて?」と迫ったところ「忙しいって言ってるのに急かされるならそもそも書きません!」的な流れになり、ココロが折れ編集モチベーションがなくなっておりました。そんなこんなで第2回から3年半、組織名も変わり新しく快く執筆を受けてくれる研究者も増え今回に至りまする。今回の著者 張翼氏は日本人?と思ってしまう程の達者な日本語力の持ち主でして、どうせならグローバルに研究成果を発信すべしとの高井部門長からのお達しにより、日本語、中国語、英語の3ヶ国語でお送りします、、、
(本文は日本語以外は基本的に本人の書いたまま。)
チョウ先鋭部門のチョウは、チョウ格好いい研究をしてまいりました。
科学の進展は、いつも新しい技術開発に頼っています。タンパク質工学の分野において、有用タンパク質の産生は、ハイスループット・スクリーニング(High-Throughput Screening, HTS)技術に大いに頼っています。ところが、既存のHTSは正確性が低く、膨大な時間とコストがかかっていました。この現状を打破して、スクリーニング作業を根本から改善したのが今回の研究成果です。
我々の共同研究チーム(JAMSTEC、東京大学、産総研、分子研)は、微細加工技術、顕微操作技術および統計学を高度に統合して、膨大なライブラリーからごく少数の優れた変異体を一発で正確に見つけ出す方法を確立しました。この方法を用いることで、たった1日で、高い正確性かつ低コストで期待の変異体を見つけることが可能となりました。
既知のタンパク質分子へ人工的に変異を導入することは、そのタンパク質機能を改善する未知の可能性を秘めています。その類の研究は、まるで自然界におけるダーウィン進化を真似ているようなので、「試験管内進化」と呼ばれています。その概念に基づいて先駆的な仕事をした研究者たちは、2018年のノーベル化学賞を授与されました。ちょうど、本研究論文を投稿する直前でした。(編集者註:参考サイト「Nature ダイジェスト」)
変異導入自体は比較的容易で速いのですが、可能性(変異のパターン)があまりにも多いため、優れた変異体を獲得するのは非常に難しいのです。タンパク質を構成する各アミノ酸部位には、20種類(天然アミノ酸は20種類)の可能性があり、例えばたった5箇所のアミノ酸をすべてカバーしたランダム変異ライブラリーには、100万種類(205)を超える変異体が含まれることになります。もし、その範囲を100個のアミノ酸に拡張したら、ライブラリー・サイズが宇宙の総原子数(1080)よりも大きくなってしまいます!一般的なタンパク質は100〜1000個程度のアミノ酸で構成されていることを考えると、タンパク質スクリーニングという作業は大海撈針のごとく、ある意味エンドレスです。「変異ライブラリー構築→スクリーニング→機能確認」といったサイクルを何度も繰り返していると、数ヶ月〜数年間かかってしまうこともあります。しかも、最終的に優れた変異体が取れる保証はまったくないので、結局何も得られないまま終わってしまうことも多々あります。運が良ければ “オイシイ” ですが、反面リスクが非常に高い研究分野なのです。
ティピカル・ハイリスク・ハイリターン。
これも、機能改善された応用価値の高いタンパク質(例えば、新規の蛍光タンパク質や酵素など)の発見が、数多く世界的に有名な科学雑誌に取り上げられている理由の一つです。それらの論文において、変異体の性能に対する評価実験は “水至りて渠成る” ことであって、如何に欲しい変異体を手に入れられるかが肝心要なところなのです。現在、有効な変異部位を確実に予測できる理論がまだ存在していないため、実験的なHTSは必然的な選択肢となっています。上述のように、スループットを如何に高めていっても、すべての可能性を探索するのは不可能である以上、本研究は、別の視点からスクリーニング分野にアプローチして、酵素活性の改善を例に、スクリーニングの正確性を上げる方法を考案しました。
ローリスク・ハイリターン!!
この方法は、ライブラリーにある各変異体の絶対発現量を測定せずに、簡単にタンパク質発現量の変動を見かけ上の酵素活性から差し引いて、確実に酵素活性が向上した変異体を識別できます。やや難しい内容ですが、ここから詳しく説明します。
私はまず、薄いガラス板に、超均一的で安定な微小液滴を、100万個/cm2 集積できる、フェムトリットル・ドロップレット・アレイ(Femtoliter Droplet Array, FemDA)という液滴作製技術を開発しました。(図 1)
FemDAのそれぞれの液滴の中には、タンパク質合成に必要なコンポーネント(鋳型DNA、転写翻訳系酵素群、等々)とタンパク質アッセイ用試薬(酵素特異的蛍光基質)を閉じ込めています。タンパク質合成の鋳型となるDNA分子は、ポアソン過程に従って、ランダムに液滴に入っていくため、それぞれの液滴に0個、1個、2個、3個……のDNA分子が含まれることになります。反応体積は、フェムトリットル・オーダー(10-15L、つまり、ナノリットル・オーダーの液滴の100万分の1)のため、タンパク質分子および酵素に分解された蛍光基質は、分子数が少なくても、高い局所的濃度を示すことになります。これは、微小空間に起因する特有の濃縮効果です。
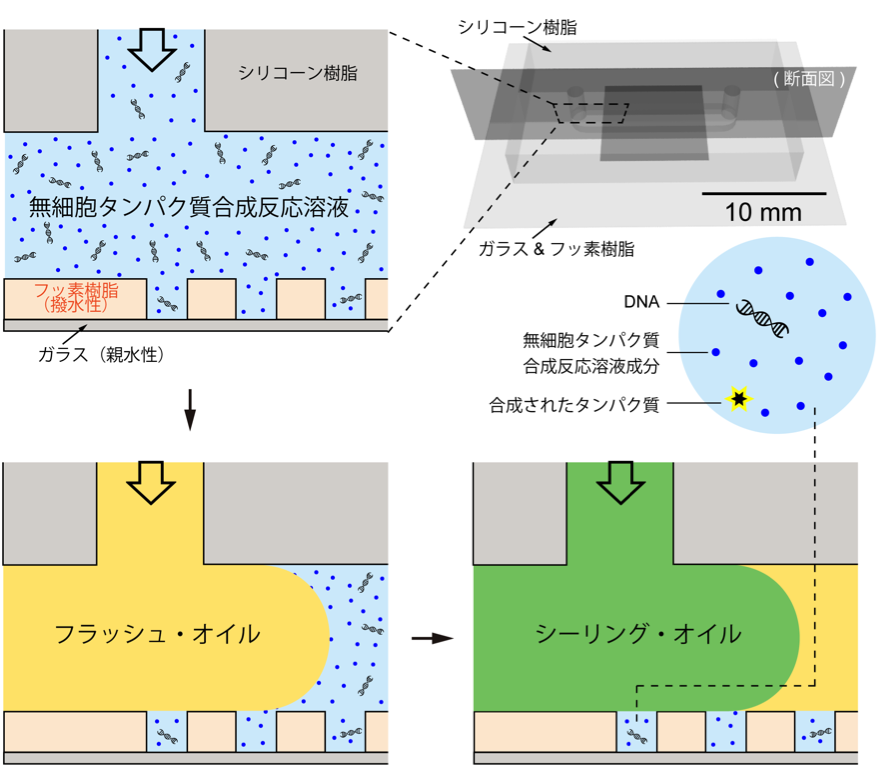
図1、フェムトリットル・ドロップレット・アレイ(FemDA)の作製。
合成された蛍光タンパク質の蛍光シグナル強度、または分解された蛍光基質の蛍光シグナル強度はリアルタイムで相対的なタンパク質合成量を反映しています。今回の実験系で無細胞タンパク質合成系におけるタンパク質合成量は、液滴中のDNA本数に綺麗に比例することが分かりました。(図 2)
これに辿り着くまでたくさんの試行錯誤があったので、「キレイだ!」と感動しました。そこで、液滴の数とDNAの濃度を事前に決めておけば、ポアソン統計学を用いて、液滴一個から得られる最大タンパク質合成量(蛍光強度による相対量)が予測できます。言い方を変えると、最多何本のDNAが一個の液滴に入ってほしいのかが決まれば、液滴の数とDNAの濃度をそれぞれ一定の閾値以下に抑える必要があります。(図 3)
そうしないと、タンパク質合成量が上がったのか、それとも酵素活性が改善されたのか、判別できなくなります。つまり、HTS実験において、単なるスループット(液滴の数)が高ければ高いほど良いわけではないのを、本研究で初めて提唱しました。
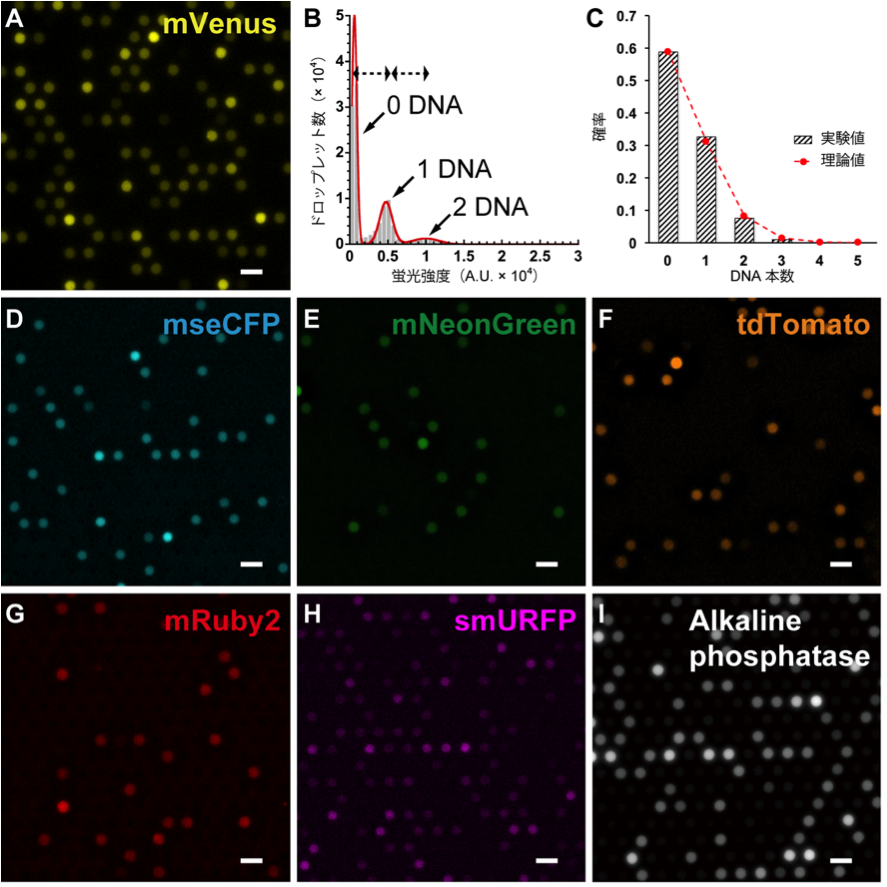
図2、FemDAによる無細胞タンパク質の合成例。[スケールバー:10 μm]
(A) 黄色蛍光タンパク質mVenus、(B)と(C)はmVenusの解析結果、(D) シアン色蛍光タンパク質mseCFP、(E) 緑色蛍光タンパク質mNeonGreen、(F) オレンジ色蛍光タンパク質tdTomato、(G) 赤色蛍光タンパク質mRuby2、(H) 遠赤色蛍光タンパク質smURFP、(I) アルカリフォスファターゼ。
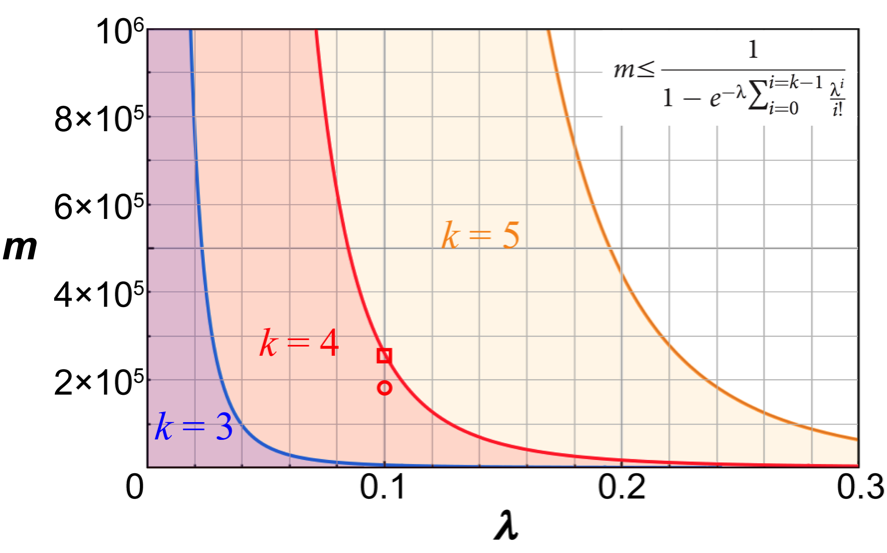
図3、デジタル・スクリーニングの数理モデル。
図中の不等式は、液滴の数(変数m)と鋳型DNAの濃度(変数λ:液滴一個あたりの平均DNA分子数)との関係を表している。パラメーターkは一つの液滴に実際に入れる最多のDNA分子数。偽陽性を回避するために、λとmは、一定の閾値以下(半透明の色付きエリア)にする必要があると一目瞭然で分かる。スクリーニングのスループット(液滴の数)が高ければ高いほど良いわけではないことが、この図でよく伝わっている。
スクリーニング実験を行う際に、液滴一個に含まれるDNAの本数がポアソン分布の制約を必ず受けていますので、もし、あるFemDAの中に、ポアソン分布で予測した最大蛍光強度を超えた液滴が現れてきたら、タンパク質合成量向上(複数本の鋳型DNAが同時にその液滴に入っている)の可能性が極めて低く、その液滴の中に優れた変異体が入っている可能性が極めて高いことを意味します。この離散的なシグナル強度分布は変異体選定基準設定時の重要な根拠になるため、私はこの方法を「デジタル・スクリーニング(Digital screeningもしくはDigital HTS)」と名付けました。これは、デジタルPCR(一分子核酸増幅による核酸定量技術、1990~1992年頃に確立された)とデジタルELISA(一分子タンパク質免疫測定によるタンパク質定量技術、2010年に確立された)と並ぶ、もう一つのデジタル・バイオテクノロジーだと提唱しています。(図 4)
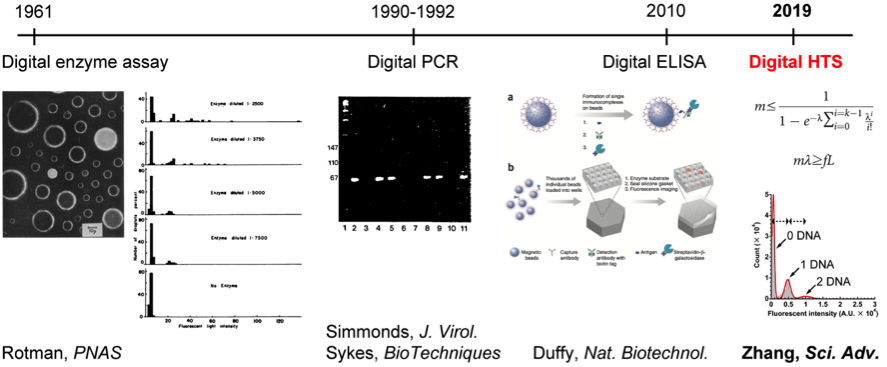
図4、デジタル化されたバイオテクノロジー。
本研究は、初めて生体分子を「検出」から「創出」へと導いた。
このデジタル・スクリーニング理論を用いて、アルカリフォスファターゼという酵素の進化実験を行いました。まずは大腸菌由来のアルカリフォスファターゼの変異体ライブラリーを作製して、そのスクリーニングを試みました。このライブラリーは48個のアミノ酸部位をカバーしていて、それぞれの変異体は変異部位を1箇所だけ持っています。コドンの縮重を含めて、それぞれの変異部位が20種類のアミノ酸に置換されるように設計しました。割と小さいライブラリーでしたが、これでも先行研究よりずっと大きいライブラリー・サイズとなっています。液滴一個当たりDNA分子が平均して0.1個入るような濃度で、変異体発現ライブラリーを18万個の液滴に導入すれば(図 3の丸い座標)、DNA分子が4個以上入る液滴の総数は1個以下になります。実際、DNA四個分相当の蛍光強度よりも強い蛍光強度を示した液滴が何個か出てきました。(図 5)
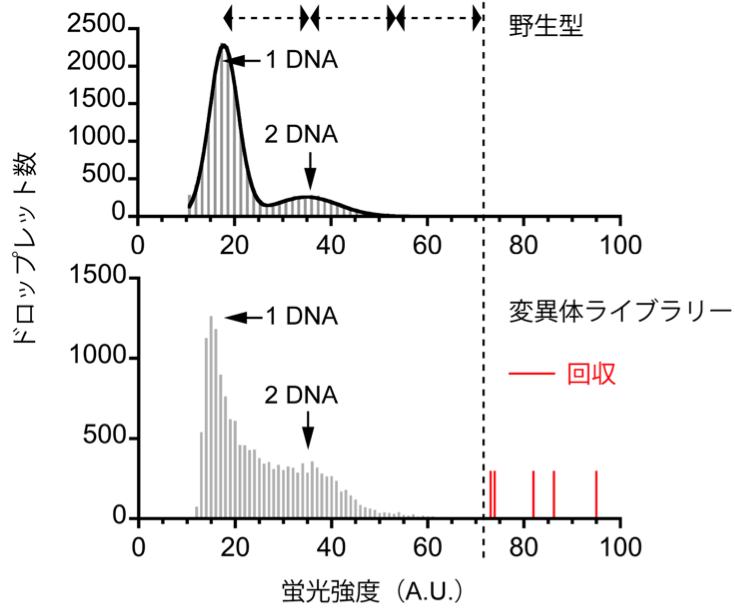
図5、アルカリフォスファターゼ変異体ライブラリーのデジタル・スクリーニング実験。
少数の液滴(赤いラベル)は、最大理論値(縦点線)を超えた蛍光強度を持っています。
これらの液滴をマイクロキャピラリーで一つずつ回収して、DNAシークエンサーでそれぞれの配列を解読しました。(図 6)
その結果、変異部位2箇所、変異体3種類が確認されました。スクリーニングから活性チェック・配列確認まで、1日で十分でした。喜ばしいことに、過去数十年の同酵素に対するスクリーニング実験から最も有効だと確認されている変異部位が再確認できたと同時に、もう一つ有効な変異部位も新しく確認できました。この変異部位は、活性中心から離れているせいか、今まで考慮に入れられたことすらなかったのです。アルカリフォスファターゼは、遺伝子組換え操作や体外診断の分野でよく使われているため、タンパク質分子構造や変異体作製の研究がたくさん行われてきました。本来この実験は、既知の有効な変異部位を大きなライブラリーから一発で見つけ出せるかどうか検証するつもりでしたが(いわゆるポジコン)、結果として既知の変異体だけでなく、これまで知られていない新しい変異体も取れました。まさしく一石二鳥!この予想外の展開は、実に興味深くて、タンパク質結晶構造から出発し構造機能相関を議論していくという古典的手法に、まだ不足があるのを強く示唆しています。網羅的に変異を導入するのは、未だ有効な戦略だと言えます。
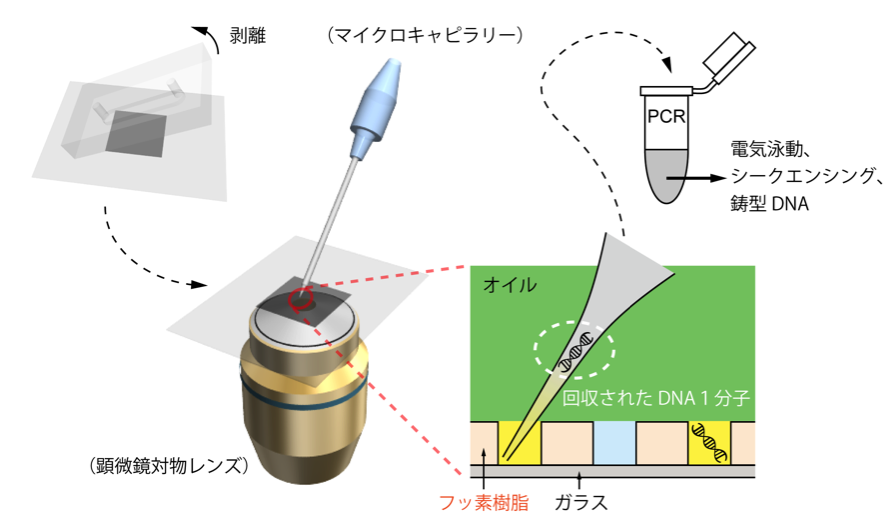
図6、マイクロキャピラリーで液滴一個からDNA一分子を回収。
回収されたDNAは、PCR増幅にかけた後、電気泳動やシークエンシングに利用できます。
デジタル・スクリーニングの数理モデルで既に示唆されたように、実験条件設定時には、境界条件(図 3の実線)が存在していて、それに近づくと、より多くの液滴(より高いスループット)を投入でき、その結果より大きいライブラリーを探索できるようになります(図 3の四角い座標に該当する実験条件は、丸い座標の場合よりスループットが高い)。この設定に基づいて、まだタンパク質分子構造が報告されていない、非モデル生物の海洋性好冷菌由来の新型アルカリフォスファターゼに注目して、その活性向上を試みました。この酵素の野生型は、既知の微生物または哺乳類由来のアルカリフォスファターゼの中で活性が一番高いとされています。活性検出用の基質として非天然のフッ素化蛍光基質を使いました。任意の250個のアミノ酸部位を広くカバーした部位飽和変異ライブラリーをスクリーニングにかけたところ、この基質に対する酵素活性が大きく改善された変異体をいくつか獲得しました。これらの変異体は、同じ変異部位を示していて、その変異部位は、20種類の天然アミノ酸の中のたった二つの強塩基性(強い正電荷を帯びている)アミノ酸にだけ置換されています。水溶液中のフッ化物の特殊な荷電性質を考えると、ここの酵素活性向上は、変異体と基質との静電相互作用の強まりから寄与されているかもしれません。これらの変異体の発見も興味深くて、活性が非常に高い酵素でも、特殊な非天然基質(自然界に選択圧が存在していないと考えられる)に対して、改善される余地が残されているのを証明しています。たった1日で進化できるなんて、面白いでしょう!
デジタル・スクリーニングは、測定の定量性が改善されて初めて可能となり、この定量性の改善は、液滴の均一性と安定性と生体適合性に由来しています。多くのスクリーニング論文はまだナノリットル(10-9 L)とピコリットル(10-12 L)の液滴技術を熱く議論している中、今回の論文はいきなり、液滴の体積を1000倍〜100万倍縮小しました。これにより必要な試薬の消耗が激減し、実験のコストが大きく下がりました(ちょっと自慢)。僅かしか存在しない優れた変異体を正確性高く絞ることができるようになるにつれて、ポスト・スクリーニングを含めたスクリーニング作業全体の労力とコストが格段と下がりました(躊躇なく、とりあえずやってみようと)。本文の最初で述べたように、変異体ライブラリーのスクリーニングには、変異の可能性が無限にあります。私たちが取り扱えるライブラリーは、あくまでもあらゆる可能性の中のごく一部に過ぎません。作製した変異体ライブラリーの中に優れた変異体が一個も存在していない可能性も十分にあります。我々のデジタル・スクリーニングは、ハイスループット・タンパク質合成反応が終わった時点で、ライブラリーに優れた変異体が存在しているかどうかが即座に判明します。たとえ優れた変異体の無い “ハズレ” ライブラリーに出会っても、無駄せず、迅速にかつ低コストで次のライブラリー作製を実施できるのです。
近い将来には、生命情報科学(バイオインフォマティックス)の進展とライブラリー作製技術の向上に伴って、今日欲しいと思った高性能タンパク質が数日後には手元に届くという、タンパク質オンデマンド作製の時代が必ずやってくるでしょう。
ページ先頭へ戻る
研究内容紹介を読んでみて Q&A
★タンパク質って何ですか?私たちの生活にどう関わっているんでしょうか?サプリメントのことですか?
-
タンパク質とは何かを詳しく説明すると、本が1冊書けてしまいます。
簡単に説明すると、
生物の遺伝情報を担うDNAは、一旦mRNAに転写され、mRNAはまたタンパク質へと翻訳されます。最終的にタンパク質は色々な機能を果たしていきます。
例えば、私たちの体の大部分は、タンパク質で構成されています。多くの疾患も、タンパク質と関わっています。酵素は生体内化学反応を触媒するタンパク質です。酵素が存在することによって、体内のすべての化学反応は、温和な条件下で行えるようになっています。生物の細胞は、実は一番素晴らしいグリーンケミストリーのファクトリーです。それらの反応を化学工場で再現しようとすると、いつも高温、高圧や有機溶媒が必要で、環境負荷も大きいです。数千年にわたって開発されてきた伝統的発酵食品(醤油・酢・酒・チーズ・ヨーグルト・パン、等々)は、例外なく、すべて酵素の働きによって出来ています。
私は普段サプリメントを使用しないのであまり詳しくありませんが、タンパク質(プロテインや酵素)を成分の一つもしくは主成分としたサプリメントもあれば、ビタミン・ミネラル・アミノ酸・植物繊維などを主成分としたサプリメントもあるようです。
★「100万種類を超える変異体」とありますが、最近よく耳にする「ビッグデータ」はもっともっと数が多い印象があります。例えばスパコンやAIを使って、ア〇ア〇マンのジャービスみたいにチェックすれば簡単に調べられるような気がするんですけど・・・
-
実は「ア〇ア〇マン」を観たことがありません。でも、言っている意味は分かります。
研究紹介の文章でも言っているように、タンパク質のアミノ酸配列の可能な数は宇宙の総原子数よりもずっと多いです。そう言った意味で、タンパク質の改造や創出は、まさしくビッグデータ・サイエンスです。
配列をどう弄ればどんな機能が得られるかは、今現在の人知で正確に予測できていません。その代わり、質問のされた様に実は、計算機もしくは機械学習を使う試みがすでに始まっています。囲碁の世界ですでに証明されたように、計算機は、過去数千年にわたって人類誰もが思いつかなかった "指し手" を見つけて、人類最強の棋士をやっつけています。囲碁でもタンパク質デザインでも、計算機は人知を遥かに超えている部分があります。
ところが、タンパク質の三次元構造と構造-機能相関は、囲碁の世界よりもずっと複雑なため、スパコンを含めた計算技術やタンパク質設計アルゴリズムは、まだ追い付いていません。期待のタンパク質分子をベストの一個まで絞れる計算技術が存在していない限り、計算機で予測した沢山の候補分子を一つ一つ合成したり、シークエンシングしたり、改変されたタンパク質の機能を再確認したりする必要があって、結果的に金銭的コストと時間的コストが非常に高いのです。今のところ、実験的アプローチのコストが計算に基づくアプローチより低いと想定される場合に限って、計算機の使用を推奨されています。
特定の酵素活性を作り出したい、もしくは特定の酵素の耐熱性を上げたいと言われた場合、コーヒーを飲みながらパソコンでクリックしてすぐに出来上がるという時代が、必ずいつかやってきますが、それに辿り着くまで、相当な時間・金銭・努力・天才が必要でしょう。過去のSF映画で描かれた技術は、本当に現実世界で実現されたものもあったので、「ア〇ア〇マンのジャービスみたいにチェックすれば簡単に調べられる」ことは、単なる夢ではないと思います。
★今回の研究成果で一番苦労した点はどこですか?FemDAの開発?それともデジタル・スクリーニング数理モデルの構築?
-
FemDA液滴作製技術の開発や数理モデルの構築に当たって、苦労をしていましたが、そういった具体的な実験や技術的な試行錯誤よりは、本研究テーマのリーダーとして、如何にこのプロジェクトを効率良く進めていけるかを考えるのに一番苦労していました。
例えば、自分の出した提案が周囲から賛同してもらえなかったら、諦めるか続行するかを経験・知識・直感で決めないといけなくて、その上で実験や試行錯誤がやっとあるわけです。また、研究費・人手・設備がなくて、実験ができない状況に置かれたことがあって、お手上げするか、それともペンと紙で理論的な仕事でも継続できるのかをじっくりと考えたところ、数理モデルの構築に辿り着いて、今回の研究の質を一気に変えました。
一般的に、研究の質を高めたければ、苦労するのが当たり前です。如何にその苦労をミニマイズするかは、創意工夫がより重要です。
★デジタルPCR/デジタルELISAに続く、新たなデジタル・バイオテクノロジーとのことですが、先述の2つはすでに分析機器として広く普及してきておりますが、既にどこかの企業と機器のリリースに向けて動いているのでしょうか?
-
今のところ、まだそんな動きが無いです。
今後、興味を示してくれる企業があったら、私としては協力する姿勢で、基礎研究の成果を積極的に社会へ還元します。
★あえて挙げるとすれば
実用化へ向けた一番大きな問題点は何ですか??
-
この社会は高度に分業化が進んでいて、人もそれぞれ役割分担をしています。
実用化に向けてどう進めていけば良いか、進めていく中で何が一番大きな問題点なのかについては、企業の経営者や研究者もしくは、起業したい方が考えるべきことだと思います。
私たちサイエンティストは、将来売り物になるかもしれない「種作り」、すなわち基礎研究に専念してサイエンスの部分を極めます。
誰がその種を何処の土に撒いて、どう美味しい米へ育ち、何時人々の食卓まで待っていけるかは、かなり複雑なことです。ビジネスモデルを事前に考えて出資元を説得しないといけません。リスクとリターンのバランスを常に考えなければなりません。
それらを全部考えくれという風潮は、近年アカデミアで強まっているように感じていますが、中国のことわざ「班門弄斧(はんもんろうふ) 」(日本では「釈迦に説法」)が言っているように、プロに任せたほうがずっと良かろうかと思います。
論文発表に伴い、私の研究の詳細が公開され企業の方を含めて誰もが読むことができます。この研究の実用化価値を認めてくれる方がいらっしゃいましたら、こちらは脇役として喜んでできる限りのことを協力します。
ページ先頭へ戻る