
昨年は、「ムーアの法則」が1965年に提唱されてから50周年に当たり、「集積回路を構成する部品であるトランジスタの集積度は24カ月(後に18ヶ月に修正)で2倍になる」というこれまでの技術向上の法則が「そろそろ終焉を迎えつつある」という切り口で、しばしばメディアにも取り上げられました。
集積度を向上させる半導体の微細化技術に物理的な限界があるのは明らかですが、興味深いのは、10年前の40周年にあたり「限界は来るが、今後4世代の技術向上は見通せる(注1)」と言っていた法則の提唱者で、インテルの創業者の一人でもあるゴードン・ムーアが、50周年のインタビューでも「今後5年から10年は見通しがある(注2)」と述べているように、半導体製造における技術革新が「限界」を先に延ばし続けていることです。 スーパーコンピュータの性能は集積度とともに自動的に上がっていくというものでもありませんが、2002年に稼働開始した初代地球シミュレータに比べて、2015年の新・地球シミュレータ(図1)が、価格対ピーク性能比で約150倍以上に向上しているのは、結果的に「ムーアの法則」にほぼ沿っている、と言えます。技術向上し続けるこの分野で、計算機を構成するプロセッサ(中央処理装置、CPU)、メモリ(記憶装置)、計算機の動作を記述するプログラムの3つのポイントでの最近の特徴的な動きについてご紹介します。

プロセッサ(CPU)製造における水平分業の進展
数千億円規模の半導体製造設備を保有して半導体の製造工程を専門に請け負う企業をファウンドリと言います。TSMC (台湾積体電路製造)、グローバルファウンドリーズなどが有名です。90年代までは、半導体の設計を行う会社が製造まで一貫して行っていましたが、微細化が進み多額の設備投資が必要になるにつれて、製造規模が大きくコスト負担に耐えられるファウンドリに製造を委託するビジネスモデル(ファブレス)が現在では主流です。例えば、「京」に使われているCPUは富士通セミコンダクター(株)三重工場で製造されました(注3)が、最新の富士通など国産メーカのCPUはiPhone用のCPUも手掛けているTSMCで製造されています。更に、2014年には、当時の最新技術を持っていたIBMが半導体事業をグローバルファウンドリーズに譲渡し、半導体売上トップのインテルも自社での設計から製造までの一貫体制から、他社の設計にも応じて製造するセミカスタマイズでファウンドリ事業を始めて生産規模の確保に動いています。
一方、スマートフォンなど携帯機器で使われる低消費電力のCPUの分野では、英国ARM社の設計するCPUが主流となっています。長らく半導体業界の売上高トップを占めるインテルは、主力のパソコン(PC)向けCPU市場が縮小する傾向で最近売上高が伸びず(注4)、勢いに陰りがみられます。ARM社は自らCPUを製造販売するのではなく、高性能なCPUを設計し、そのライセンスと設計データを半導体製造会社に売っています。それを購入した各社は、ARM社のライセンスに基づきCPUを製品化しますが、自社でカスタマイズすることも出来ます。現在、iPhone、iPad、Galaxy、Xperia、ニンテンドー3DSなどに、ARM社の設計方式(アーキテクチャ)に基づくCPUが使われていますが、今後、スーパーコンピュータの分野でも、低消費電力のARM社のアーキテクチャが広がっていくものと思われます。
このように、設計段階での水平分業化が進展してきたため、自社の設計方式をオープン化してパートナー企業を募る動きにIBMとインテルも乗り出してきています。IBMは、2013年に「Open Power Foundation」を設立し、IBMの技術の普及とメンバー間の協業を推進しており、現在121の企業、大学、研究機関がメンバーとなっています。また、インテルも自社の設計を提供して他社がそれを組み込むことが出来るようなサービスを開始しています。(注5)
現在のところ、パートナー企業が独自のCPUをARMやIBM、インテルの設計方式を使って開発し、商用のスーパーコンピュータに搭載した例を私は知りませんが、ファブレスのビジネスモデルで身軽になったメーカが、このような機会を活かして自社の特長のあるCPUを創り出す可能性が増えていく状況となっています。
メモリの多様化と多層化
パソコン、サーバを始めとする情報機器の主記憶装置には、コンデンサとトランジスタを構成単位としていて微細化・大容量化に有利な記憶素子DRAM(ダイナミック・ランダム・アクセス・メモリ)が用いられていますが、構成単位間の干渉と静電容量の減少が原因で微細化が限界に近付きつつあります。また、CPUとメモリとの間の標準的なデータ転送方式も、DDR-DDR2-DDR3-DDR4と進化していますが、微細化でCPUの性能が向上するほどには、データ転送の性能は改善されていきません。これらの問題を解決する新しい技術として3次元積層メモリ、広帯域メモリ、不揮発性メモリなど多様な記憶素子が現れ、従来型のDRAMと併せて、用途ごとに利用されていく方向です。
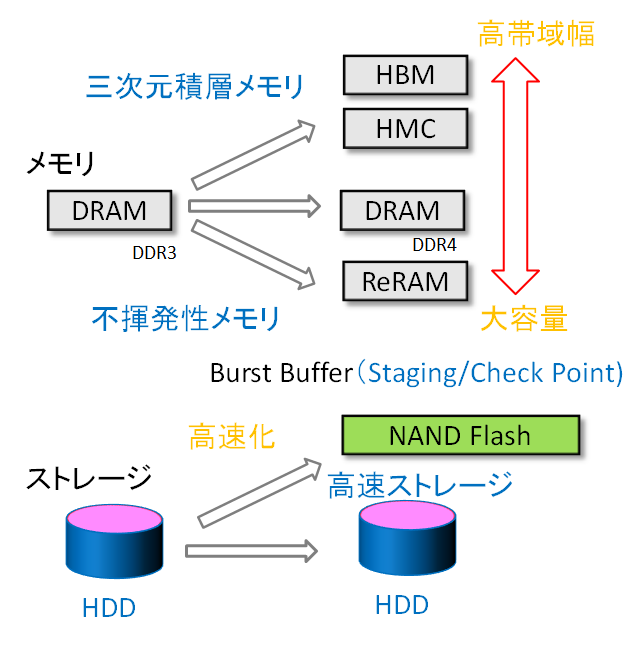
3次元積層メモリは、通常平面的に回路が配置されているLSIを切り離して垂直方向に積層し、その間の配線にLSIの基盤であるシリコンの内部を貫通する電極を用いるもので、小型化・高密度化とデータ転送性能の向上に寄与します。現在High-Bandwidth Memory(HBM)とHybrid Memory Cube(HMC)の二つの規格が製品化されつつあります。HBMとHMCは、ともに高いデータ転送性能を実現する広帯域メモリです。8GB~32GB程度と記憶容量が小さく、まだコストが高いのが難点です。容量単価が安く、大容量化の可能な不揮発性メモリとしては、身近なUSBメモリにも使われているNANDフラッシュや可変抵抗型メモリ(ReRAM)などが有り、積層型NANDフラッシュも発表されています。NANDフラッシュは、DRAMと比べ書き出し性能が格段に遅い問題がありますが、次世代技術のReRAM(可変抵抗型メモリ)はDRAMとそん色ないデータ転送性能と言われています。また、CPUと同じパッケージの上に、広帯域メモリを搭載する計画もインテルなどから発表されています。
従来計算機の中のデータは、メモリ(DRAM)にあるか、ストレージ(ファイル:HDD)にあるか、の二段の階層になっていましたが、CPUと密に結合した広帯域メモリ、従来型のDRAM、大容量のReRAM、NANDフラッシュなどを、例えばそれぞれ、高速メモリ領域、通常メモリ領域、入出力データを仮置きする機能(ステージング)や計算途中結果を保存する機能(チェックポイント)のための装置(Burst Buffer)、高速ストレージとして多段の階層で使い別け、CPUの高性能化に伴う大量のデータ転送の問題に対処することが考えられます(図2)。各メーカにとっては、どのようなメモリとストレージをどのように配置し、ソフトウェアを通してどのような使い勝手をユーザに提供するかがスーパーコンピュータを設計する上での工夫のしどころであり、そこで各社が差異化を図るので、ユーザにとっては多様なシステムから最適なものを選ぶことが出来るようになっていくと思われます。
プログラムの課題
CPUのLSIをよくみると、実際には一つではなく、複数のCPUで出来ていることがありますが、このような「CPUの中のCPU」をコアまたはCPUコアと呼びます。図1の地球シミュレータのCPUには4つのコアがあります。よく知られているように、2004年頃からCPUの動作周波数は上がっておらず、スーパーコンピュータの高速化はもっぱら数多くのCPUコアを並列につなげて動作させ、更にコアの内部の演算器を並列に動作させることで達成されています。別の言い方をすれば「質より量で勝負」といえます。スーパーコンピュータ用のCPUで圧倒的なシェアを持つインテルは、並列動作の仕組みの一つとして配列計算を高速に行うことの出来るベクトル演算機能を強化しており、インテルの次世代のCPUでは、8要素のベクトル演算を行う命令が二つ同時に実行出来るようになると言われています。この演算機能は、256要素のベクトル演算が四つ同時に実行出来て100倍以上の容量のベクトルレジスタを備える現在の地球シミュレータとは作りが違います。しかし、次世代のインテル製CPUで仕様通りの性能を出すには、ベクトル演算機能を活用する必要があります。そのためには、プログラムの中の計算を配列計算の繰り返しで行うように自動的にあるいは手動で書き換えること(ベクトル化)がポイントの一つになると見られます。ところが米国などで開発されてきたプログラムは、しばしば、ベクトル演算機能を意識して作られていないため、ベクトル化率(全計算の中でベクトル演算機能を利用する割合)が低い場合が多く、今後のプログラムの性能を向上させるための技術的な課題の一つです。よく報道などでも引用される世界のスーパーコンピュータ番付「TOP500」は、「Linpack」という比較簡単なプログラムによる性能評価に基づいていますが、スーパーコンピュータの「Linpack」の性能は、搭載するCPUの設計上の上限値の総和である理論ピーク性能に近い値になることが知られています。この値が実用的なアプリケーションプログラムの性能を現しているとは言えない、との反省から、これとは別に、より実用的な性能評価手法「HPCGベンチマーク」が提案されています。昨年11月の世界的なスーパーコンピュータ会議「SC15」で、この「HPCGベンチマーク」の結果発表がありました。地球シミュレータは、21位の性能でしたが、消費電力あたりの性能はトップクラスであり、ピーク性能に対する実効性能が10%を超えることと併せて、「Vector returns!」と発表の中で特に紹介されたのは、ベクトル機能が再度注目されてきている動向を背景としたものです。(注6)
また、グラフィックス表示のための計算のためのプロセッサであるGPU(グラフィックス・プロセッシング・ユニット)が進化して、スーパーコンピュータにも利用されています。スーパーコンピュータに導入されているGPUは、数千個の演算器を備え、一つの命令で多数の演算を同時に行う仕組みになっています。また、2.で述べたような、記憶容量は小さいが、データ転送性能の非常に高いメモリと接続されています。GPUは、汎用のCPUに付属して計算処理の部分を受け持つ加速機構として動作する仕組みのため、CPUとデータをやりとりする接続インタフェースの性能向上や、通常のプログラムをGPUの仕様に合わせて書きなおさなくてはならないことが課題です。
上で述べた、「スーパーコンピュータの高速化のため多くのCPUコアを並列に動作させ、更にコアの内部の演算器を並列に動作させる」には、ユーザがコンピュータ内部の動きを考慮に入れながら処理手順をプログラムで詳細に記述する必要があり、コンピュータと計算の方法の両方についての専門的な知識が必要となるため、使い方が難しくなっています。このような作業を容易にするためのツールや言語処理系のソフトウェアの開発が課題ですが、なかなか充実にはほど遠いのが現状です。上で述べたようなベクトル演算機能やGPUについて、スーパーコンピュータの各メーカは、過去に手掛けたベクトル型スーパーコンピュータの技術を使うことが出来ると言っており、初代から現在の三代目の地球シミュレータまで、ベクトル型のスーパーコンピュータを利用しているJAMSTECがその点で優位に立つ可能性もあり、今後の動向から目が離せない状況です。
以上、最近のスーパーコンピュータに関わる特徴的な業界や技術の動きを3つのポイントでご紹介しました。大規模計算システムでは冷却設備なども含めた電力コストも課題であり、電力あたりの計算効率やデータ転送効率が良いシステムの開発も、スーパーコンピュータ技術の大きなテーマになっています。後者の、大量のデータを高速に移動させることや、そのようなデータ移動を最小限にするようにシステムを設計することは、メモリ、ストレージ、ネットワークを含めた情報システムの全体設計に関わる根本的な課題と言えます。
日本では、2014年から「フラッグシップ2020プロジェクト」が発足し、ポスト「京」の開発が推進されています。現在インテルのCPUを使った世界最大のスーパーコンピュータ「天河二号」を持つ中国、技術をリードし今後10年間に30億ドルの国家予算をスーパーコンピュータ開発につぎ込むという米国、ともに2017年から2018年に、一段と大規模なシステムを導入することを発表しています。特に米国エネルギー省の主導するプロジェクトでは、ここに述べたような新しい技術が積極的に採用される計画であることが公表されており、実際のアプリケーションプログラムがどこまで性能を伸ばせるのか、非常に興味深いところです。
これまで、標準的なスーパーコンピュータは、インテルのCPUを高速ネットワークで結合したクラスター型のものでしたが、今後は、多様な技術を組み合わせた特徴のあるシステムが現れ、スーパーコンピュータのメーカにとってもユーザにとっても、選択の幅が大きく、ユーザが最適なものを選び取る時代になってくるものと思います。JAMSTECの将来の計算環境に向けて、今後とも技術動向を注視して行きたいと考えています。
謝辞
本稿をまとめるにあたり、文部科学省科学技術・学術政策研究所科学技術動向研究センターの野村稔氏に、多くの情報と教示をいただきました。ここに御礼申し上げます。
脚注
(注1)Moore, G. E. (2006) 「Understanding Moore’s Law: four decades of innovation」, Philadelphia, Chemical Heritage Press, p.84.
(注2)Damon Poeter. (2015年5月12日)「Gordon Moore Predicts 10 More Years for Moore’s Law」, PCMAG.COM
(注3)「USJC 拠点紹介/沿革」
(注4)福田昭. (2016年1月16日) 「売上高でインテルの後を追うSamsungとHynixの脅威」, PC Watch
(注5)「Intel Custom Foundry」, p6, Intel 2014 Annual Report
(注6)Jack Dongarra, Michael Heroux, Piotr Luszczek. (2015年11月11日) 「HPCG UPDATE: SC’15」
この記事をシェア
へぇ〜となったり、発見があったり。
誰かの「知ってよかった!」につながるかも?