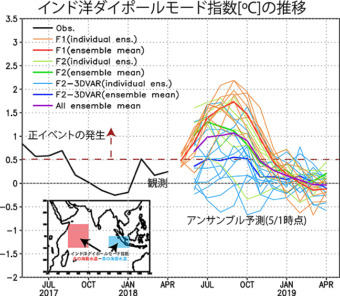
近年、体感としても感じられるようになった「地球温暖化」。2040年代には夏に北極海の氷がなくなる日が来るともいわれています。このような地球の気候をシミュレーションするプログラムが「気候モデル」と呼ばれるもので、世界中で開発が進められています。この気候モデルはどのような仕組みで作られ、どのように開発・改良されているのか?さらには、気候モデルから何がわかるのか? 海洋研究開発機構(JAMSTEC)の地球環境部門 環境変動予測研究センターの河宮未知生センター長にお話を聞いてみました。(取材・文:岡田仁志)

地球で起こる気象現象を数式で記述する
──JAMSTECの「地球シミュレータ」のようなコンピュータを使って、気象や気候の変化を予測するシミュレーションモデルは、どのようにつくるのでしょうか?
気象や気候は物理現象なので、まず、気象にかかわる物理法則を理解することが大切です。 気象現象は、大気や海洋の循環、水が蒸発して雲になって雨を降らせるといった状態の変化や熱の移動などを、運動方程式、気体の状態方程式、放射伝達方程式、あるいは熱力学第一法則などの物理法則を土台とした数式で表現することができます。それらの数式をコンピュータに解かせるのが、シミュレーションモデルですね。
日々の天気予報や数年程度の短いスパンのシミュレーションをするものは「気象モデル」、地球温暖化のような100年〜200年という長いスパンのシミュレーションを行うものを「気候モデル」と呼び分けることが多いです。
また、気候モデルの場合は「全球モデル」といって、地球全体を計算するモデルが一般的ですが、気象モデルの場合は、日本なら日本とその周辺というように、知りたい範囲に限定して計算されることも多くあります。
地球を細かなメッシュで区切っていく
数式をコンピュータに解かせるためには、「離散化」という作業が必要になります。線グラフを描くときに、飛び飛びの点と点をつないでいくのと同じようなことです。
たとえば全球を対象とする気候モデルをつくるなら、まず地球の表面全体をたくさんの格子に区切ります。その1つ1つのマス目ごとに、気温や水温、風速、水蒸気、海水の塩分など、気候に関わる量の時間的な変化を計算できるようにプログラムを組んで、コンピュータに教えてあげるんです。

──格子のサイズはどうのように決めるのでしょう?
マス目が小さいほど、きめ細かいシミュレーションができます。しかしその分、計算量が増えるので時間がかかってしまうんですね。ですから、地球温暖化予測のようにスパンが長く、全球(地球全体)での計算を行う 気候モデルは、マス目の1辺が数十キロメートル〜100キロメートルの大きな格子で区切ります。
一方、毎日の天気予報などきめ細かい情報が必要な気象モデルは、1辺が数キロメートル〜数十キロメートルの細かい格子で区切るのが一般的です。
観測データを用いた「パラメータ化」という手法
──気候モデルにも、さまざまな種類があるそうですが、それぞれコンピュータに解き方を指示するプログラムが違うということでしょうか?
そういうことです。シミュレーションに使う方程式は世界各国の研究グループすべて共通なので、どのプログラムでも同じですが、その一方で、モデルには観測データに基づく経験則が含まれます。同じ現象に対して複数の経験則が提案されていることも少なくありません。その中のどれを選ぶかによって、プログラムは変わってくるわけです。
たとえば、「積雲対流」という現象があります。海面で温められた空気が上昇して大気が上下に混ぜられ、入道雲(積雲)をつくるような現象です。これは水平方向に数キロメートルの狭い領域で生じるので、それよりも大きな格子で区切っている多くの気候モデルでは表せません
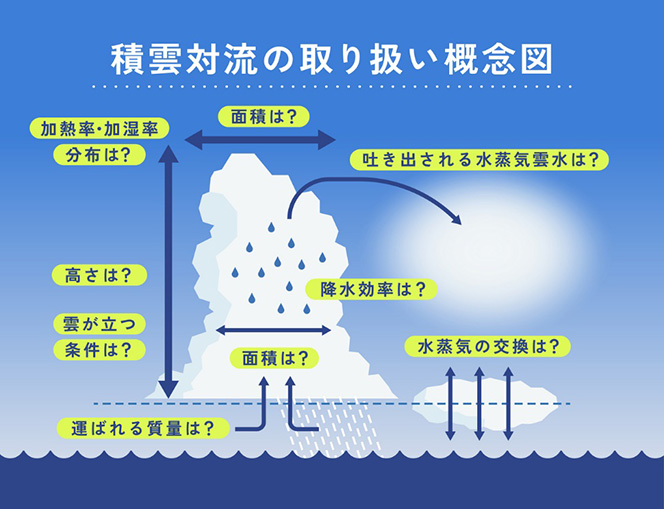
しかし、1つ1つは小さくても、積雲対流は常にあちこちで起きているので、全部を合わせると地球全体の熱や水蒸気などの分布に大きな影響を与えます。マス目の大きい地球温暖化予測モデルでも、それを無視することはできません。とはいえマス目を小さくすれば、計算に時間がかかりすぎます。
そこで次善の策として導入するのが、経験則です。「過去のデータから見て、この状況では積雲対流がこれくらいの頻度で起きているはずだ」とコンピュータに教えてあげるんですね。これを「パラメータ化」といいます。
積雲対流だけではありません。海に生じる渦や森林から放出される水蒸気の量など、経験則によるパラメータ化を行うものはいろいろあります。
もちろん、パラメータ化は科学的な根拠に基づいたものですが、ひと通りに決めることはできません。シミュレーションモデルを開発する研究所によって、流儀や考え方が異なります。それぞれ数式に現れる定数の値や式の形そのものに違いがあるので、いろいろな気候モデルができあがるわけです。
シミュレーションの精度を高める「データ同化」
──決まった方程式はあっても、自然現象の変化を正確に計算するには、すべてコンピュータ任せというわけにはいかないんですね。
なかなか簡単にはいきません。実際に、気候シミュレーションモデルを動かすときは、さまざまな手法で上空、地表、海洋などから集めた観測データを、マス目の緯度、経度、鉛直方向にきれいに並べたデータセットが、予測のスタート地点になります。
でも、観測は場所によって時刻や精度にバラつきがありますし、気候モデルも自然を完璧にコピーしているわけではないので、どうしてもズレが出てしまうんですね。
そのズレを補正して、シミュレーション結果を観測データに近づけるためには、「データ同化」という作業も必要になります。
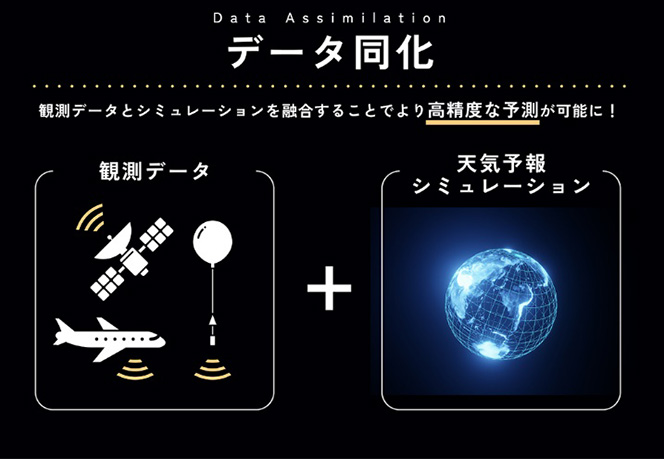
やり方はさまざまですが、いったんシミュレーションモデルを動かしてから、その結果をある地点の観測データと比較して、両者を足して2で割ったような条件を設定することもあります。その上で、あらためてそこをスタート地点にしてシミュレーションを行うわけです。
モデルが拒絶反応を起こすことがある!
気候モデルでも、ズレがあるときに「観測データはこうだよ」と無理やり結果をそちらに近づけようとすると、シミュレーションモデルが拒否反応を起こすこともあるんですよ。
なるべく観測データに近いフィールドからシミュレーションモデルに予測させたいわけですが、あまり近づけすぎると、モデルは自分のフィールドから離れることにショックを受けて、ポーンと自分の好きなフィールドに近づこうとするんです。
そういう振る舞いをさせないように、「あなたの気持ちもわかりますけど、観測データはこうなので、ちょっとこっちに近づいてもらえませんかね?」という気持ちで(笑)、足して2で割るようにしながらバランスを取るのが、すごく難しいところです。
──拒否反応を起こすと聞くと、コンピュータに人格があるかのように感じられて、不思議な気がします。
計算機ですから、教えられた方程式で「素直な解」との違いが大きい数値を与えられると、振る舞いがおかしくなるんです。
実際の観測値をそのまま入れても、「素直な解」が成り立たないケースがほとんどなんですよ。計算機は方程式を何とか成り立たせようとがんばりますが、無理して方程式を成り立たせようとするときに振る舞いがおかしくなるんです。 観測データには測定誤差がありますし、いろいろなノイズも入りますから。
たとえば池の水の流れをシミュレーションするために観測データを集めているときに、誰かがその池に小石をポチャンと投げ込むと、いつもとは違う波が生じますよね。そういう偶発的なイベントのデータが「素直ではない解」にあたり、その池における全体的な流れ(「素直な解」にあたります)を知りたいときには、見たくないわけです。

でも、観測で拾ったデータが、知りたいものなのか、偶発的なイベントによるものなのかは区別がつきません。シミュレーションモデルの結果を見るときは、偶発的なイベントとは関係のない全体的な流れに注目したいケースがほとんどなので、そういう観測データをそのまま与えると、不具合を起こしやすいんです。
「アンサンブルデータ」と「カオス現象」の計算
──シミュレーションを始めるときの初期値を少しずつ変えて、同じような予測実験を何度も何度も行うこともあるそうですね。これは、なぜ必要なのでしょう?
「アンサンブル計算」と呼んでいる手法のことですね。その意味合いを理解するためには、「カオス」と呼ばれる現象のことを知ってもらう必要があります。
カオスは、1960年代のはじめ頃に、米国の気象学者エドワード・ローレンツが発見しました。きっかけは、気象現象の研究のためのシミュレーションモデルで同じ初期値をもとにした計算を2度やったところ、まったく異なった結果が得られたこと。これはコンピュータの誤作動ではなく、同じだと思って入力したはずの初期値がわずか5000分の1ほど違っていたせいでした。
この経験から生まれたのが、カオスの概念です。ローレンツは、大気の流れを表す方程式を大幅に簡略化した3つの式で、物体の動きを計算しました。それをグラフにすると、蝶が羽を広げたような形になります。のちに「ローレンツ・アトラクタ」と名付けられた有名な形です。
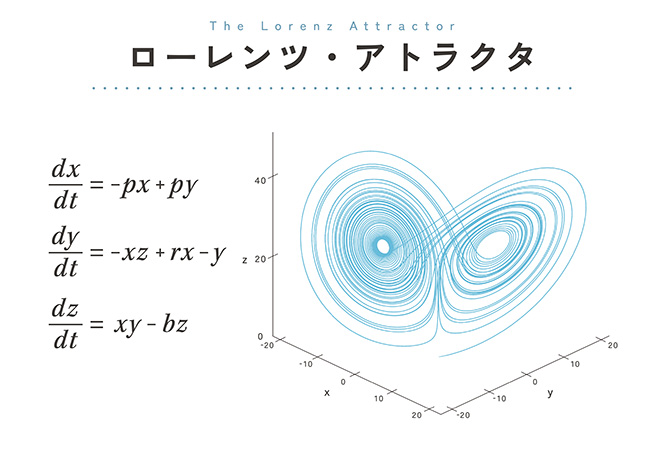
物体は、一方の羽の上をぐるぐる回ったかと思うと、突然もう一方の羽に移動してそちらでぐるぐる回り始めたりなど、予測不可能な動きをします。
また、物体の出発点をほんの少しだけずらして動かし始めると、最初のうちは前と似たような軌跡を描きますが、やがてどんどん離れていって、まったく違う場所を動き回るようになります。ただし、ローレンツ・アトラクタから飛び出すことはありません。
気候というカオス現象を予測するには
こうしたカオス性は、日常的な場面にもあります。たとえば木の葉が落ちていくコースや地面に落ちる場所を完璧に予測するのは、簡単ではありません。「だいたい、このあたりに落ちる」という程度は予測できますが、それがどこなのかを正確に言い当てることはできませんよね。
また、同じ場所から同じように落としても、木の葉が描く軌跡はいつも違います。手から放すときの力の入れ具合や角度、そのときの空気の流れなど、初期値がほんの少し違うだけで、木の葉の動き方はまったく違ったものになるわけです。
ですから、ある1点を指して「確実にここに落ちる」と予測することはできません。そこで初期値を少しずつ変えたシミュレーションをたくさん行い、その平均を取って「だいたいこのあたりに落ちる」と予測するのが、アンサンブル計算です。
いわば、たくさんのサイコロを振るようなものですね。振ったサイコロの数が多いほど、信頼できる予測になります。その1つ1つの実験のことを、「アンサンブルのメンバー」と呼んでいます。
100年後の地球がなぜわかるのか?
──具体的には、どのようにして初期値の違う「メンバー」を増やすのでしょうか。
先ほど、観測データとシミュレーションモデルの結果を足して2で割りながら初期値をつくる「データ同化」のお話をしました。このときに、時刻の違う結果をいくつも取り出して初期値にするのが一般的です。
ただし、メンバーが多いほど計算に時間がかかりますから、多ければよいというものでもありません。適切なメンバー数は、求められる予測精度の高さと計算時間のバランスで決まります。天気の週間予報や台風情報などは、50ぐらいのメンバー数。メンバーの多くが同じようなシミュレーション結果を示すほど、信頼度が高いといえます。
――そういう工夫をしても台風の進路予想はかなりの幅がありますから、やはり気象や気候のシミュレーションは難しいんですね。
よく「1週間先の天気もわからないのに、100年後にどこまで温暖化が進むかを予測できるのか?」と疑問を抱かれることがありますが、むしろ1週間先の天気予報のほうが難しい面があります。
そちらのほうが初期値に敏感に反応するので、予報できる期間に限界があるんですね。一方、100年後の温暖化予測は、長い期間にわたる気候の統計量を対象にするので、ある程度の予測が可能なんですよ。
次の記事「近年の猛暑は予測されていたのか?地球温暖化における人間活動の影響は?「気候モデル」研究でわかる地球の未来とは」では、実際にJAMSTECで研究されている気候モデルから、どのようなことがわかるのかを伺ってみます。

取材・文:岡田仁志
撮影:村田克己(講談社写真部)
図版作成:酒井春
取材協力・図版提供:環境変動予測研究センター 河宮未知生 センター長
この記事をシェア
へぇ〜となったり、発見があったり。
誰かの「知ってよかった!」につながるかも?
この連載のほかの記事を読む
- “100のパラレルワールド”で猛暑の原因を探る。「イベントアトリビューション」×「高解像度モデル」で地球温暖化の影響を評価するには

- 日本近海に大量のマイクロプラスチックが降り積もっている!?太平洋から北極海にまで流れ込んでいる、その量を観測データから推定すると
- 「カオス現象」の気候はどのように予測されるのか?「気候モデル」で100年後の地球の気温を予測する方法
- 近年の猛暑は予測されていたのか?地球温暖化における人間活動の影響は?「気候モデル」研究でわかる地球の未来とは
- これがプレート境界下側「海洋プレート」の地質コア試料の「玄武岩」だ!12年前に残った地震研究の謎の解明へ【「JTRACK」研究航海終了!】